


Vincent Liu
Engineering the Future of Translation Automation: Phase 1 Results
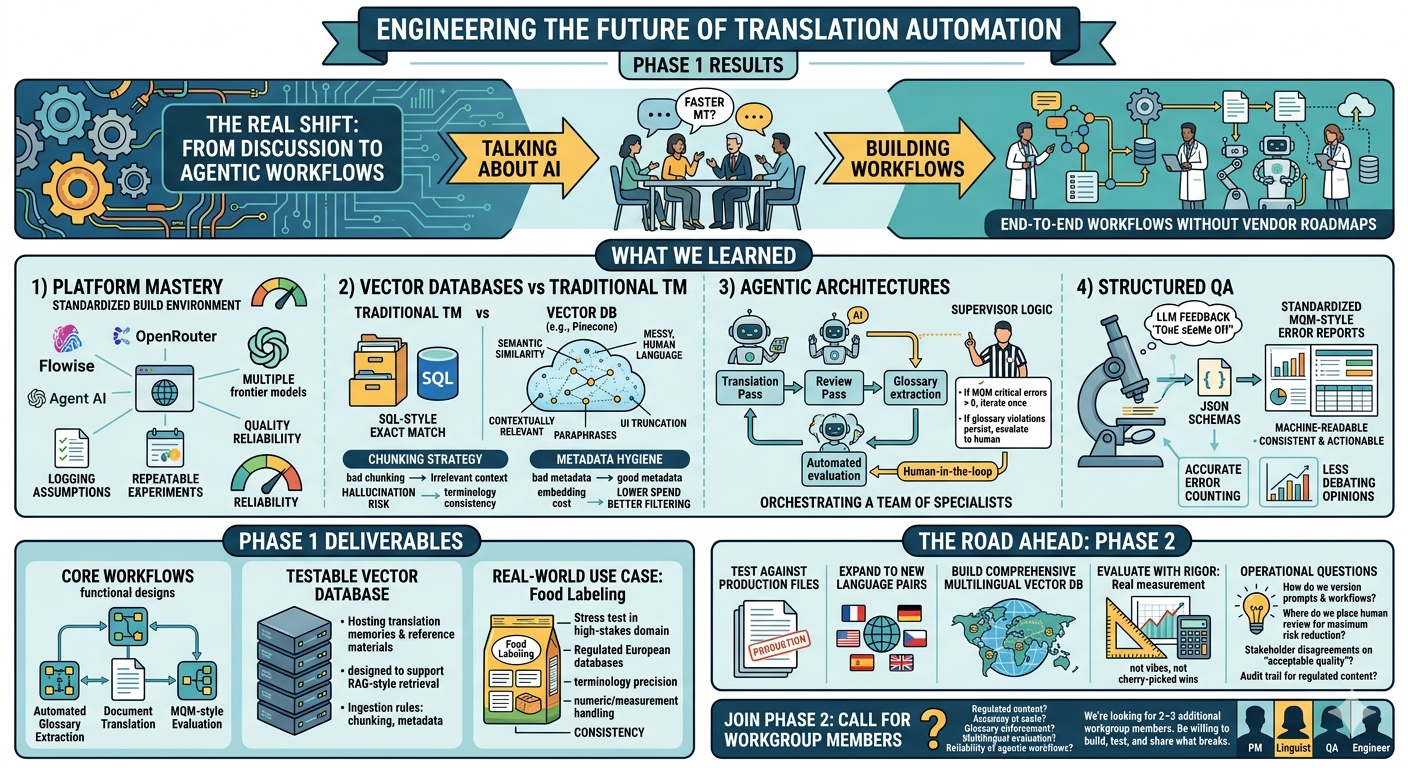
The first phase of ourworkgroup has officially concluded. Over the past twelve working sessions, wemoved from discussing the theory of AI-augmented workflows to buildingfunctional, agentic systems that tackle the practical challenges of modernlocalization.
The Evolutionof the Workgroup
We launched on November 3,2025, sparked by a critical shift in the industry. As noted in Intento’s TheState of Translation Automation 2025 report, Large Language Models(LLMs) now dominate the landscape, accounting for 89% of top-performingtranslation systems—a massive leap from just 55% in 2024.
Our mission was to movebeyond the hype and architect the requirement-driven workflows described inthat research. What began as a collaborative brainstorming group evolved into atechnical laboratory where "active builders" experimented with no-code/low-codemulti-agent platforms to achieve the 80–90% error reduction rates thatcustomization and Retrieval-Augmented Generation (RAG) now make possible.
TechnicalMilestones & Knowledge Gained
Throughout this phase, thegroup tackled a steep learning curve in AI orchestration:
● Platform Mastery: We standardized our development on Flowise, utilizing OpenRouterfor flexible access to the frontier models identified as top performers in theIntento study.
● Vector Databases vs. Traditional TM: We explored the shift fromSQL-based "exact match" searches to semantic similarity usingvector databases like Pinecone. We learned that while vector searchesare superior for finding contextually relevant segments, they requiresophisticated "chunking" strategies to maintain system performance.
● Agentic Architectures: Following the industry trend toward full-text translation,we moved away from segment-by-segment processing. Our workflows now use AIsupervisors to manage loops of translation, glossary adherence, and automatedreview.
● Structured Quality Assurance: We implemented JSONschemas to force LLMs into generating standardized MQM-style error reports,ensuring that AI-generated feedback is machine-readable and actionable.
Phase 1 Deliverables
The group successfullyachieved several tangible outputs:
1. Three Core Workflows: Functional designs for automated Glossary Extraction, DocumentTranslation, and MQM-style Evaluation.
2. A Testable Vector Database: A practical implementation for hosting translation memoriesand reference materials.
3. Real-World Use Case: A "Food Labeling"project leveraging regulated European databases to test AI accuracy in highlyspecialized, high-stakes contexts.
Acknowledgments
This progress would not havebeen possible without the dedicated contributions of our core workgroupmembers. We would like to extend a special thank you to:
● Vincent Liu, for his leadership in forming the group, providing technicaldemonstrations in Flowise, and drafting our architectural frameworks.
● Chantal Kamgne, for her insights into workflow implementation and consistentengagement in refining our automation strategies.
● Vasso Pouli, for her contributions to the linguistic quality and evaluativeaspects of the project.
● Nick Lambson, for his technicalperspective and collaboration in testing the limits of these new agentic tools.
What’s Next for Phase 2?
As we transition into thenext stage, the focus shifts toward scaling and evaluation. Our goalsinclude testing these workflows against actual production files, expanding tonew language pairs, and building out a comprehensive multilingual vectordatabase.
We have moved from beingobservers of the AI shift to being the architects of it.
.png)




